



- Co to jest plik robots.txt? Plik robots.txt jest po prostu plikiem TXT, który żyje w katalogu głównym...
- Dlaczego ten plik jest tak ważny?
- Czy potrzebujesz tego technicznie?
- Formatowanie i reguły Robots.txt
- Dyrektywy
- Link do mapy witryny
- Najważniejsze wskazówki dotyczące konfigurowania pliku robots.txt pod kątem SEO?
- 2. Wyłącz tylko pliki i katalogi witryn, których nie chcesz indeksować
- 3. Nie wolno zabronić dostępu do całej witryny, chyba że naprawdę nie chcesz, aby była ona indeksowana
- 4. Nie blokuj plików CSS, Javascript lub Image za pomocą pliku robots.txt (chyba że istnieje konkretny powód, aby to zrobić)
- 5. Zawsze dołącz link do lokalizacji podstawowej mapy witryny XML lub indeksu map witryn
- 6. Przejrzyj proponowane reguły robots.txt w korzystaniu z narzędzia testowego Google Robots.txt przed opublikowaniem na żywo w produkcji
- 7. Regularnie przeglądaj (i aktualizuj w razie potrzeby) plik robots.txt, aby upewnić się, że nie występują żadne problemy
- 8. Użyj w połączeniu ze znacznikiem noindex na stronie, aby uzyskać najlepszą kontrolę nad indeksowaniem
- Zalecana konfiguracja dla WordPressa?
- Dodatkowe zasoby Robots.txt
Co to jest plik robots.txt?
Plik robots.txt jest po prostu plikiem TXT, który żyje w katalogu głównym witryny, który dostarcza wyszukiwarkom informacji o tym, które części witryny mogą indeksować.
Co ważniejsze, mówi robotom internetowym, które obszary witryny nie mają mieć do nich dostępu.
Kilka historycznych i praktycznych uwag na temat standardu pliku robots.txt:
- Plik /robots.txt jest de facto standardem i nie jest własnością żadnego organu normalizacyjnego. Istnieją dwa historyczne opisy: oryginalny 1994 Standard wyłączenia robota dokument i specyfikacja Internet Draft z 1997 roku Metoda kontroli robotów internetowych
- Niektóre dodatkowe zasoby zewnętrzne: Specyfikacja HTML 4.01 , Dodatek B.4.1, oraz Wikipedia - Standard wykluczania robotów
- Różne przeszukiwacze mogą inaczej interpretować składnię
- Standard /robots.txt nie jest aktywnie rozwijany.
- Roboty internetowe mogą zignorować /robots.txt witryny. Jest to szczególnie powszechne w przypadku szkodliwych robotów szukających luk w zabezpieczeniach.
- Plik /robots.txt jest publicznie dostępnym plikiem. Oznacza to, że każdy może zobaczyć, które sekcje twojego serwera nie chcą używać robotów, więc nie próbuj używać /robots.txt do ukrywania informacji.
- Dyrektywy robots.txt nie mogą zapobiec odwołaniom do adresów URL z innych witryn
Gdzie można znaleźć plik robots.txt?
W katalogu głównym Twojej witryny. Jako przykład, oto moja:
Dlaczego ten plik jest tak ważny?
Plik robots.txt kontroluje bezpośrednio indeksowanie, a jeśli zostanie niewłaściwie potraktowany, może pozwolić na całkowite deindeksowanie witryny (lub jej części) lub wyświetlanie suboptymalnie stron wyników wyszukiwania (SERP).
Chociaż z pewnością nie jest to najbardziej efektowny aspekt SEO, plik robots.txt może potencjalnie wpłynąć na wydajność SEO.
Czy potrzebujesz tego technicznie?
Nie, brak pliku robots.txt nie zabrania wyszukiwarkom indeksowania Twojej witryny.
Zalecałbym jednak posiadanie takiego, ponieważ był to standard internetowy od ponad 20 lat, może on pozwolić na kontrolowanie indeksacji witryny, a za jej pomocą możesz przesyłać krytyczne strony do wyszukiwarek za pomocą mapy witryny XML.
Formatowanie i reguły Robots.txt
Aplikacje użytkownika
Po pierwsze, wszystkie pliki robots.txt muszą mieć agenta użytkownika, który określa, do których sekcji mają być stosowane reguły.
Użycie [su_highlight] User-agent: * [/ su_highlight] dotyczy wszystkich robotów internetowych.
Agent użytkownika: *
Możesz jednak kierować na określone boty za pomocą określonych reguł. Oto przykład kierowania na [su_highlight] Googlebot [/ su_highlight]:
User-agent: Googlebot
Zobacz listę wszystkie programy użytkownika / roboty internetowe . Uwaga: w jednym pliku robots.txt można dołączyć wiele agentów użytkownika z unikalnymi regułami.
Dyrektywy
Poniżej znajdują się przykłady użycia pliku robots.txt do kontrolowania indeksowania witryny lub określonych folderów.
Aby zablokować robotom indeksującym dostęp do całej zawartości witryny
User-agent: * Disallow: /
Aby umożliwić robotom indeksującym dostęp do całej zawartości witryny
User-agent: * Disallow:
Aby wykluczyć roboty indeksujące z dostępu do określonych folderów i stron
User-agent: * Disallow: / wp-content / Disallow: / wp-plugins / Disallow: /example-folder/example.html
Aby wykluczyć jednego robota z indeksowania, ale pozwól innym
User-agent: * Disallow: User-agent: Baiduspider Disallow: /
Aby wykluczyć dostęp do określonego folderu, ale zezwalaj na określone typy plików
User-agent: * Disallow: / example / Allow: /example/*.jpg Allow: /example/*.gif Allow: /example/*.png Allow: /example/*.css Allow: /example/*.js
Chociaż technicznie nie ma atrybutu [su_highlight] Allow [/ su_highlight], użyłem tej metody i działa.
W rzeczywistości jest to przykładowy zrzut ekranu działający na mojej stronie (zgodnie z testerem Google Robots.txt).
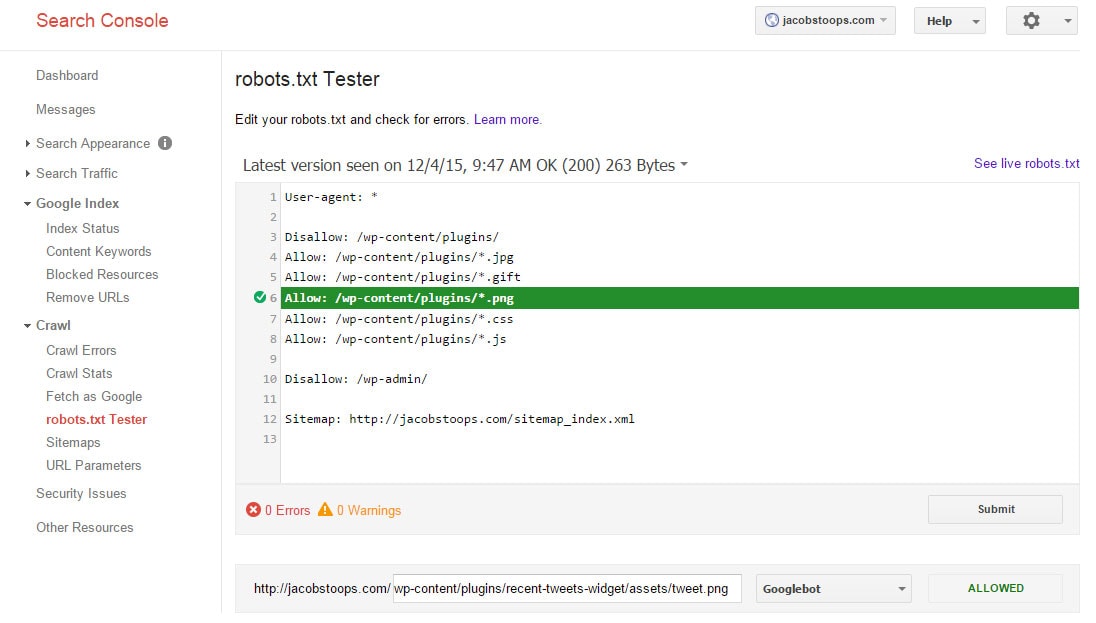
Aby zezwolić na dostęp do określonego folderu, ale wykluczyć pewne typy plików
Odwrotnie do powyższej metody.
User-agent: * Zezwól: / wp-content / plugins / Disallow: /wp-content/plugins/*.png
Aby uniemożliwić dostęp do określonego typu pliku
User-agent: * Disallow: /*.gif$
Z pewnością istnieje więcej sposobów na dostosowanie pliku robots.txt, ale powinny one zacząć działać.
Link do mapy witryny
Poniżej znajduje się format dodawania linku do mapy witryny XML witryny.
User-agent: * Disallow: Mapa strony: https://jacobstoops.com/sitemap_index.xml
Najważniejsze wskazówki dotyczące konfigurowania pliku robots.txt pod kątem SEO?
1. Musi mieć nazwę robots.txt, musi być plikiem TXT i musi znajdować się w katalogu głównym witryny (np. Example.com/robots.txt)
Należy zastosować następujące konwencje zapisywania, aby roboty indeksujące mogły znaleźć i zidentyfikować plik robots.txt. Na przykład, ponieważ przeszukiwacze szukają tego pliku tylko w katalogu głównym witryny, jeśli zapiszesz go w podkatalogu (np. Example.com/directory/robots.txt), nie będą go używać.
2. Wyłącz tylko pliki i katalogi witryn, których nie chcesz indeksować
Na przykład, jeśli masz katalogi, które mogłyby prowadzić do problemów z duplikatami treści, możesz użyć pliku robots.txt do kontrolowania indeksacji tych plików.
Dodatkowo, prawdopodobnie rozsądnie jest zabronić indeksowania plików, które zawierają poufne dane, takie jak numery telefonów, informacje o transakcjach itp. (Chociaż te rzeczy są prawdopodobnie lepiej kontrolowane przez HTTPS).
3. Nie wolno zabronić dostępu do całej witryny, chyba że naprawdę nie chcesz, aby była ona indeksowana
To prawdopodobnie największy „nie-nie” po stronie SEO. Niestety tak się dzieje.
[su_note note_color = ”# EFEFEF”] Przykłady klientów: W moim ~ 10-letnim doświadczeniu pamiętam to co najmniej 2 razy - jedno z małą witryną i jedno z dużą witryną e-commerce. W obu przypadkach witryny były prawie całkowicie dezindeksowane przez pewien okres, aw przypadku dużej witryny handlu elektronicznego konsekwencje związane z przychodami z wyszukiwania naturalnego były bardzo poważne.
Również w obu przypadkach zmiana pochodzi od kogoś spoza zespołu SEO, co sugeruje, że może nie do końca rozumieli, co robią. Oba przypadki były niefortunnymi niepowodzeniami dla odpowiednich programów SEO. [/ Su_note]
4. Nie blokuj plików CSS, Javascript lub Image za pomocą pliku robots.txt (chyba że istnieje konkretny powód, aby to zrobić)
W październiku 2014 r. Google zaktualizował swoje wskazówki techniczne dla webmasterów dotyczące indeksowania CSS, JavaScript, obrazów itp .
Oto co powiedzieli:
[su_quote] Niedopuszczanie do indeksowania plików JavaScript lub CSS w robots.txt Twojej witryny bezpośrednio szkodzi temu, jak dobrze nasze algorytmy renderują i indeksują twoją zawartość i mogą skutkować suboptymalnym rankingiem. [/ su_quote]
Aby sprawdzić, czy blokujesz krytyczne zasoby, możesz użyć raportu Zablokowane zasoby Google Search Console:
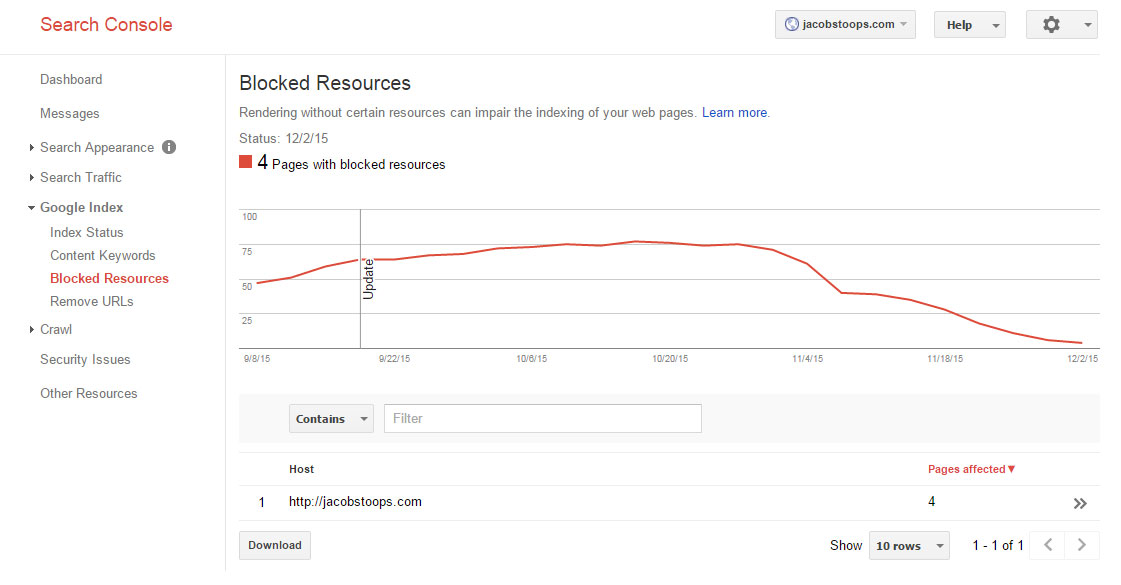
5. Zawsze dołącz link do lokalizacji podstawowej mapy witryny XML lub indeksu map witryn
Jest to świetny sposób, aby wyszukiwarki mogły uzyskać dostęp do mapy witryny XML Twojej witryny, zwłaszcza jeśli nie przesłałeś jej jeszcze za pomocą Google Search Console.
6. Przejrzyj proponowane reguły robots.txt w korzystaniu z narzędzia testowego Google Robots.txt przed opublikowaniem na żywo w produkcji
Pomoże to zapewnić, że żadne ważne strony nie blokują przypadkowo dostępu do wyszukiwarki.
Widzieć: https://support.google.com/webmasters/answer/6062598?hl=pl&ref_topic=6061961
7. Regularnie przeglądaj (i aktualizuj w razie potrzeby) plik robots.txt, aby upewnić się, że nie występują żadne problemy
Wiele rzeczy może się zdarzyć w trakcie wdrażania, wydań kodu itp. Przeglądanie pliku robots.txt w połączeniu spowoduje, że narzędzia takie jak Google Search Console może zapewnić odpowiednią obsługę indeksowania witryny i konfiguracji pliku robots.txt.
8. Użyj w połączeniu ze znacznikiem noindex na stronie, aby uzyskać najlepszą kontrolę nad indeksowaniem
Blokowanie indeksowania adresów URL za pomocą pliku robots.txt nie może zabraniać wyświetlania tych stron / plików jako wykazów adresów URL tylko w SERP - zwłaszcza jeśli strony zostały zindeksowane przed ich wykluczeniem.
Jeśli strona jest już indeksowana, ale jest zablokowana - w SERP pojawi się następujący komunikat:
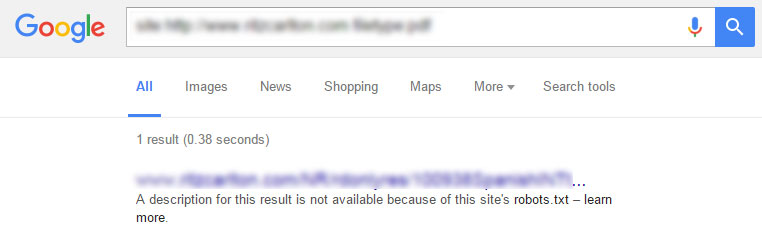
Najlepszym rozwiązaniem dla całkowitego zablokowania indeksu danej strony jest użycie robotów [su_highlight] meta noindex [/ su_highlight] na stronie wraz z plikiem robots.txt.
Jest to najlepszy sposób, aby w pierwszej kolejności zatrzymać strony w indeksie, lub aby strony już indeksowane były usuwane.
Zalecana konfiguracja dla WordPressa?
Jeśli korzystasz z WordPress, edytowanie pliku robots.txt za pomocą FTP lub wtyczki, takiej jak Yoast SEO dla Worpress, jest bardzo proste. Po prostu wykonaj następujące kroki, aby wprowadzić zmiany w pliku robots.txt .
Jeśli chodzi o najlepszy sposób konfiguracji, istnieje wiele sposobów na oczyszczenie kota.
Oto jak skonfigurowałem moje:
User-agent: * Disallow: / wp-content / plugins / Allow: /wp-content/plugins/*.jpg Allow: /wp-content/plugins/*.gif Allow: /wp-content/plugins/*.png Allow: /wp-content/plugins/*.css Allow: /wp-content/plugins/*.js Disallow: / wp-admin / Sitemap: https://jacobstoops.com/sitemap_index.xml
Upewniłem się, że kluczowa zawartość zostanie przeszukana, ale ta konfiguracja zapewni, że kluczowe katalogi są blokowane, podczas gdy indeksowane są takie rzeczy, jak Javascript, CSS i obrazy.
Dodałem również link do mojego pliku indeksu map witryn XML.
Dodatkowe zasoby Robots.txt
Kredyt obrazkowy: Dysk e-News
Txt?Dlaczego ten plik jest tak ważny?
Czy potrzebujesz tego technicznie?
Txt pod kątem SEO?
Txt?
Txt?
Czy potrzebujesz tego technicznie?
Txt pod kątem SEO?
Com/webmasters/answer/6062598?
Zalecana konfiguracja dla WordPressa?