



- Питання індексації файлів PDF
- Як шукати PDF-файли в Google
- Файли PDF можуть відображатися навіть у вибраних фрагментах
- Інші типи файлів, індексовані компанією Google
У недавній відеокімнаті Google Джон Мюллер підтвердив, що вони індексують файли PDF так само, як і інші веб-сторінки . Джон Мюллер також зрозумів, чому такий файл PDF не може бути проіндексований, незважаючи на це.
У чаті Hangouts було задано наступне запитання 18:48 :
Питання: Я не можу отримати багато моїх PDF-файлів, індексованих на моїх сторінках продукту. Чи потрібно просто додавати вміст на вкладці свого продукту, так що це в обох місцях? Чи призведе це до дублювання питань і будь-якої ідеї, чому вони не будуть індексувати?
Джон Мюллер : Загалом, ми індексуємо PDF-файли, як би хотіли інші звичайні сторінки на веб-сайті. Те, що, можливо, станеться з PDF-файлами, полягає в тому, що ми не так часто оновлюємо їх, як звичайні сторінки HTML, оскільки припускаємо, що файли PDF залишаться стабільними. Але це не схоже на вашу проблему. Що стосується індексації файлів PDF, якщо ми бачимо посилання на ці сторінки, ми спробуємо індексувати ці сторінки, щоб отримати їх у результати пошуку.
Джон Мюллер : Тому, якщо ми не зможемо індексувати ці сторінки, то у нас виникнуть проблеми з пошуком посилань на ті файли PDF, які можуть бути через те, що їх важко знайти на веб-сайті, або, можливо, вони не в статичному HTML-коді або у них є nofollow посилання або щось подібне. Або просто ми говоримо, що вміст індексовано з вашого сайту вже достатньо. Ми ще не готові додати значний пакет додаткового вмісту. Тому ми не можемо гарантувати, що ми індексуємо весь вміст веб-сайту, а це означає, що для деяких веб-сайтів, у деяких ситуаціях, ми можемо мати відсічення і сказати, що ми вже індексували багато контенту з цього веб-сайту. Ми продовжуватимемо сканувати більше вмісту з цього веб-сайту, і якщо ми знайдемо щось дійсно переконливе, ми включимо це також у індекс. Можливо, ці PDF-файли є вмістом, який ми розглянули, або вмістом, якого ми не мали часу для перегляду на веб-сайті.
Джон Мюллер : Якщо є важливий вміст у тих PDF-файлах, які вам потрібно проіндексувати, то варто звернути увагу на сторінку продукту безпосередньо. Таким чином, люди не повинні завантажувати PDF-файл, щоб побачити цей вміст. Так що якщо це важливо, можливо, покладіть його прямо на сторінку. Якщо це більш допоміжний вміст, наприклад, довідковий матеріал, який люди могли б побачити, але не потрібно класифікувати окремо, то, можливо, це нормально, просто посилаючись на ваші сторінки продуктів.
Ви можете переглянути відповідну частину обговорення нижче:
Питання індексації файлів PDF
Це не перший випадок, коли виникає проблема індексації PDF-файлів. В Повідомлення веб-майстра Центрального блогу ще у вересні 2011 року Гарі Ілліс (Google Gary) відповів на деякі запитання про індексацію PDF, які ми підсумуємо нижче:
Загалом, так, Google сканує PDF-файли, якщо вони не захищені паролем або зашифровані. Якщо текст вбудовано як зображення, Google може обробляти ці зображення для видобування тексту. Загальне правило полягає в тому, що якщо ви можете скопіювати текст з PDF документа, Google повинен мати можливість шукати вміст у форматі PDF та індексувати його.
Зображення в PDF-файлах не індексуються (станом на 2011 рік).
Посилання обробляються так само, як посилання на веб-сторінках. Вони передають PageRank та інші сигнали індексації і будуть дотримуватися при скануванні. Посилання в PDF-файлі неможливо.
Ви повинні додати "X-Robots-Tag: noindex" у заголовку HTTP, який використовується для обслуговування файлу. Якщо вони вже проіндексовані, то реалізований заголовок змусить їх випасти з плином часу. Крім того, ви можете використовувати Інструмент видалення URL .
PDF-файли можуть бути подібними до веб-сторінок.
Google використовує метадані заголовків у файлі та прив'язку тексту посилань, що вказують на файл PDF. Google рекомендує встановити обидві.
Як шукати PDF-файли в Google
Як шукати PDF-файли в Google
- Використовуйте оператор типу файлу для пошуку файлів PDF
Якщо ви бажаєте шукати PDF-файли в Google, ви можете скористатися оператором "filetype:".
Для пошуку PDF-файлів для пошукового терміну "SEO PDF" введіть наступне:
- filetype: pdf SEO PDF
- Потім натисніть "Пошук Google".
- На сторінці результатів SERP показано PDF у верхньому індексі ліворуч від кожного результату
На скріншоті можна побачити знімок екрана.
Файли PDF можуть відображатися навіть у вибраних фрагментах
17 січня 2019 р. Кевін Індіг повідомив про Twitter тепер Google використовує фрагменти з файлів PDF.
Я спробував цей приклад, і він продовжував працювати станом на 26 січня. Нижче наведено знімок екрана:
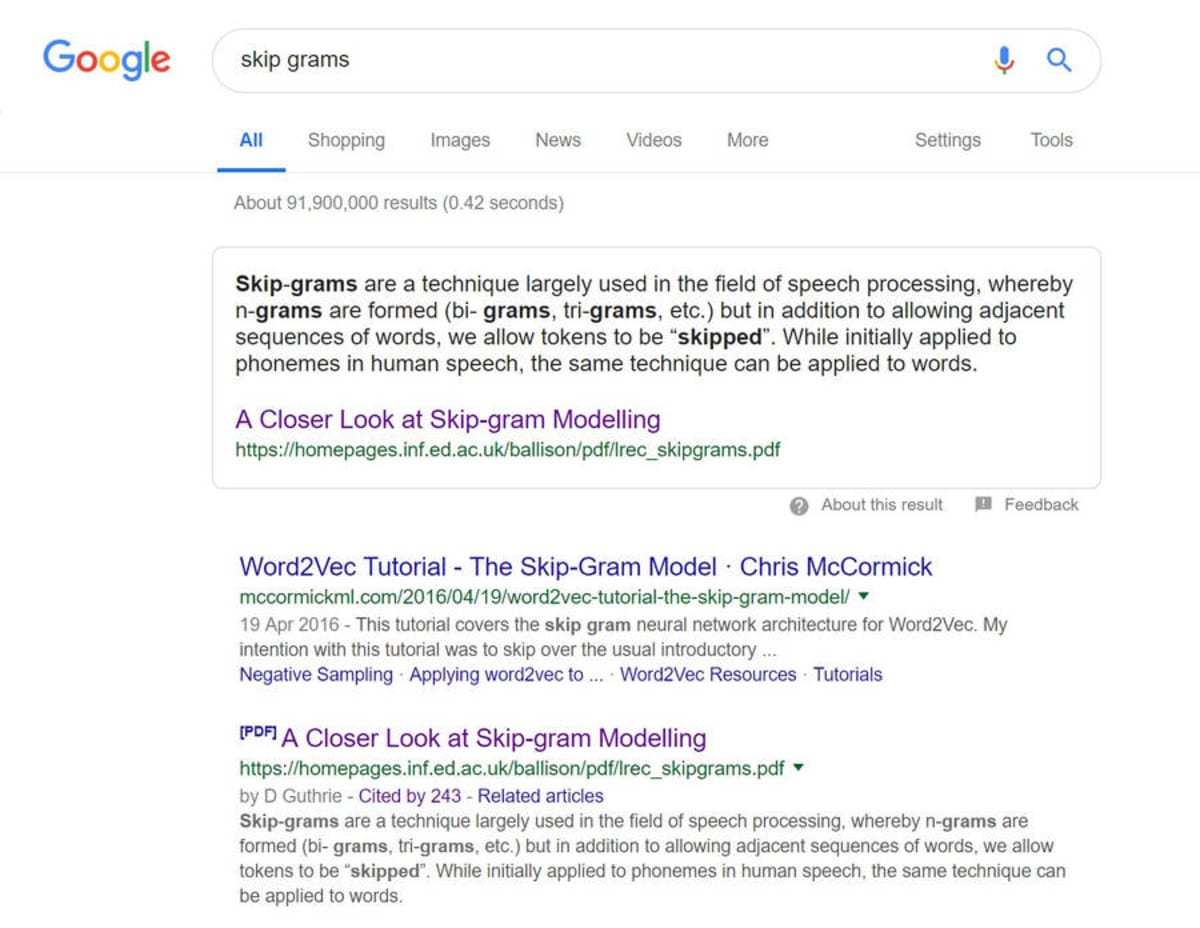
Пропоновані фрагменти з PDF, що показуються в Google. © Веб-майстер
Ви можете посперечатися в своєму житті, що багато спеціалістів SEO тепер будуть оптимізувати свій PDF для пошукових систем.
Інші типи файлів, індексовані компанією Google
PDF-файли є лише одним з великої кількості типів файлів, які можна індексувати Google.
Google може індексувати вміст більшості типів сторінок і файлів, включаючи Adobe Flash, документи Microsoft, такі як Excel і Docs, формат Rich Text, документи OpenOffice, PowerPoint і різні мови програмування.
Ви можете знайти повний список файли, що індексуються тут .
Чи потрібно просто додавати вміст на вкладці свого продукту, так що це в обох місцях?Чи призведе це до дублювання питань і будь-якої ідеї, чому вони не будуть індексувати?