



- Що таке файл robots.txt? Файл robots.txt - це просто TXT-файл, що знаходиться на корені вашого сайту,...
- Чому цей файл настільки важливий?
- Ви технічно це потребуєте?
- Формування & правила Robots.txt
- Директиви
- Посилання на карту сайту
- Кращі способи налаштування файлу robots.txt для SEO?
- 2. Виключайте лише файли та каталоги сайтів, які ви не бажаєте індексувати
- 3. Не забороняйте доступ до всього сайту, якщо ви дійсно не хочете, щоб він сканувався
- 4. Не блокуйте файли CSS, Javascript або Зображення за допомогою файлу robots.txt (окрім випадків,...
- 5. Завжди вказуйте посилання на місце розташування основного XML-мапи сайту або індексу мапи сайту
- 6. Перегляньте запропоновані правила robots.txt, використовуючи інструмент тестування Robots.txt від...
- 7. Регулярно переглядайте (і оновлюйте, якщо необхідно) файл robots.txt, щоб переконатися, що жодних...
- 8. Використовуйте разом з тегом noindex на сторінці для кращого керування індексацією
- Рекомендована конфігурація для WordPress?
- Додаткові ресурси Robots.txt
Що таке файл robots.txt?
Файл robots.txt - це просто TXT-файл, що знаходиться на корені вашого сайту, який надає пошуковим системам інформацію про те, які частини вашого сайту вони можуть сканувати.
Що ще важливіше, він повідомляє веб-роботам, які області сайту, до яких ви не хочете, щоб вони мали доступ.
Кілька історичних і практичних приміток щодо стандартного файлу robots.txt:
- /Robots.txt є де-факто стандартом і не належить жодному органу стандартизації. Є два історичні описи: оригінал 1994 року Стандарт для виключення роботів документ, а також специфікацію веб-проекту 1997 року Метод керування веб-роботами
- Деякі додаткові зовнішні ресурси: Специфікація HTML 4.01 , Додаток B.4.1, та Вікіпедія - Стандарт виключення роботів
- Різні сканери можуть по-різному інтерпретувати синтаксис
- Стандарт /robots.txt не активно розвивається.
- Веб-роботи можуть ігнорувати /robots.txt вашого сайту. Це особливо часто зустрічається з роботами-зловмисниками, які шукають уразливості безпеки.
- Файл /robots.txt є загальнодоступним файлом. Це означає, що будь-хто може бачити, які розділи вашого сервера ви не хочете використовувати для роботи, тому не намагайтеся використовувати /robots.txt, щоб приховати інформацію.
- Ваші директиви robots.txt не можуть запобігти посиланням на ваші URL-адреси з інших сайтів
Де можна знайти файл robots.txt?
У кореневому каталозі вашого сайту. Як приклад, тут мій:
Чому цей файл настільки важливий?
Файл robots.txt безпосередньо керує індексацією, а якщо неналежним чином обробляється, може дозволити вашому сайту (або його частинам) повністю деіндексировать або відобразити під-оптимально у сторінках результатів пошуку (SERP's).
Хоча це, звичайно, не самий гламурний аспект SEO, ваш файл robots.txt має потенціал, щоб бути досить впливовим для продуктивності SEO.
Ви технічно це потребуєте?
Ні, відсутність файлу robots.txt не заборонятиме пошуковим системам сканування вашого веб-сайту.
Тим не менш, я настійно рекомендував би один, оскільки він був веб-стандартом на 20 + років, він може дозволити вам контролювати індексацію вашого сайту, і ви можете використовувати його для подачі критичних сторінок пошуковим системам через XML-карту сайту.
Формування & правила Robots.txt
Агенти користувачів
По-перше, всі файли robots.txt повинні мати користувальницький агент, який визначає, до яких розділів повинні застосовуватися правила.
Використання [su_highlight] User-agent: * [/ su_highlight] застосовується до всіх веб-роботів.
User-agent: *
Тим не менш, ви можете націлювати конкретні боти за допомогою певних правил. Ось приклад націлювання на [su_highlight] Googlebot [/ su_highlight]:
User-agent: Googlebot
Див. Список всі агенти користувача / веб-роботи . Як примітку, ви можете включити декілька агентів користувачів з унікальними правилами для кожного в одному файлі robots.txt.
Директиви
Нижче наведено кілька прикладів використання файлу robots.txt для керування індексацією вашого сайту або певних папок.
Щоб заблокувати доступ сканерів до всього вмісту сайту
User-agent: * Disallow: /
Щоб дозволити сканерам доступ до всього вмісту сайту
User-agent: * Disallow:
Щоб виключити сканери для доступу до певних папок і сторінок
Агент користувача: * Disallow: / wp-content / Disallow: / wp-plugins / Disallow: /example-folder/example.html
Щоб виключити окремий робот від сканування, але дозволяйте іншим
User-agent: * Disallow: User-agent: Baiduspider Disallow: /
Щоб виключити доступ до певної папки, але дозволити певні типи файлів
User-agent: * Disallow: / example / Allow: /example/*.jpg Дозволити: /example/*.gif Дозволити: /example/*.png Дозволити: /example/*.css Дозволити: /example/*.js
Хоча технічно немає атрибута [su_highlight] Allow [/ su_highlight], я використав цей метод і він працює.
Насправді, тут наведений приклад знімка екрана, який працює на моєму сайті (відповідно до інструменту тестування Robots.txt від Google).
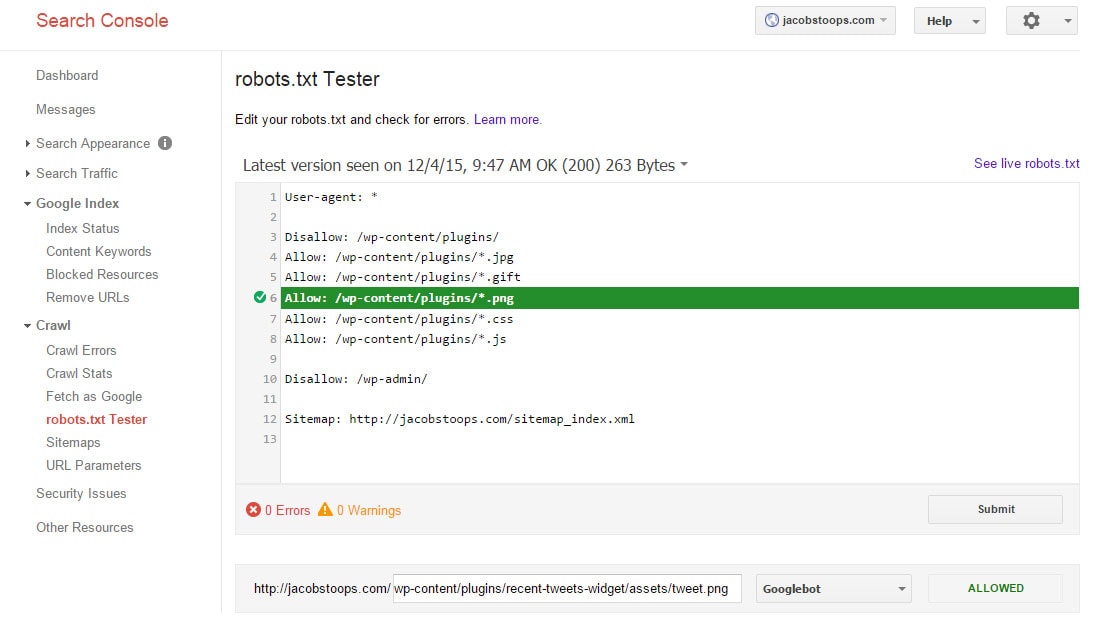
Щоб дозволити доступ до певної папки, але виключити певні типи файлів
Просто протилежність вищевказаного методу.
User-agent: * Дозволити: / wp-content / plugins / Disallow: /wp-content/plugins/*.png
Щоб заборонити доступ до певного типу файлу
User-agent: * Disallow: /*.gif
Звичайно, ви можете налаштувати файл robots.txt, але вам слід розпочати роботу.
Посилання на карту сайту
Нижче наведено формат додавання посилання на XML-карту сайту.
User-agent: * Disallow: Sitemap: https://jacobstoops.com/sitemap_index.xml
Кращі способи налаштування файлу robots.txt для SEO?
1. Він повинен бути названий robots.txt, повинен бути TXT-файлом і повинен знаходитися в кореневому каталозі вашого сайту (наприклад, example.com/robots.txt)
Необхідно застосувати наступні правила збереження, щоб веб-сканери могли знайти і ідентифікувати файл robots.txt. Наприклад, оскільки сканери шукають цей файл лише в кореневому каталозі сайту, якщо ви збережете його в підкаталозі (наприклад, example.com/directory/robots.txt), вони його не використовуватимуть.
2. Виключайте лише файли та каталоги сайтів, які ви не бажаєте індексувати
Наприклад, якщо у вас є каталоги, які призводять до дубльованих проблем із вмістом, ви можете скористатися файлом robots.txt для керування ними.
Крім того, можливо, доцільно заборонити індексацію файлів, які містять конфіденційні дані, такі як телефонні номери, інформацію про транзакції тощо (хоча ці речі, можливо, краще контролюються через HTTPS).
3. Не забороняйте доступ до всього сайту, якщо ви дійсно не хочете, щоб він сканувався
Це, мабуть, найбільший "ні-ні" на стороні SEO. На жаль, це трапляється.
[su_note note_color = "# EFEFEF"] Приклади клієнтів: У моєму десятирічному досвіді я пам'ятаю, що це відбувається принаймні 2 рази - один з невеликим сайтом і один з великим сайтом електронної торгівлі. В обох випадках сайти були майже повністю деіндековані протягом періоду, а у випадку великого сайту електронної торгівлі, наслідки надходжень від природного пошуку були надзвичайно серйозними.
Крім того, в обох випадках, зміни прийшли від кого-то за межами команди SEO, що натякає, що, можливо, вони не повністю зрозуміли, що вони роблять. Обидва випадки були невдалими невдачами для відповідних програм SEO. [/ Su_note]
4. Не блокуйте файли CSS, Javascript або Зображення за допомогою файлу robots.txt (окрім випадків, коли для цього є певна причина)
У жовтні 2014 року Google оновили свої технічні рекомендації для веб-майстрів щодо індексування CSS, JavaScript, зображень тощо .
Ось що вони сказали:
[su_quote] Заборона сканування файлів Javascript або CSS у файлі robots.txt вашого сайту безпосередньо шкодить тому, як наші алгоритми відтворюють та індексують ваш вміст, і можуть призвести до неоптимального рейтингу. [/ su_quote]
Щоб дізнатися, чи блокуєте будь-які критичні ресурси, можна скористатися звітом Заблоковані ресурси консолі пошуку Google:
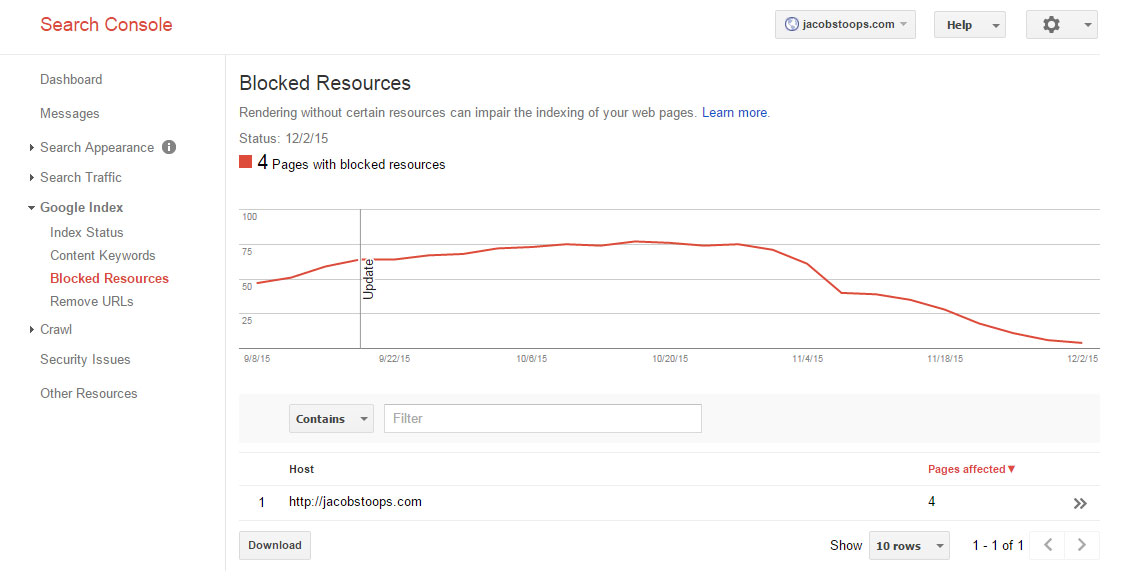
5. Завжди вказуйте посилання на місце розташування основного XML-мапи сайту або індексу мапи сайту
Це відмінний спосіб для пошукових систем отримати доступ до XML-сайту сайту вашого сайту, особливо якщо ви ще не подали його через консоль пошуку Google.
6. Перегляньте запропоновані правила robots.txt, використовуючи інструмент тестування Robots.txt від Google до публікації в реальному часі
Це допоможе переконатися, що жодна важлива сторінка не випадково блокує доступ до пошукової системи.
Подивитися: https://support.google.com/webmasters/answer/6062598?hl=uk&ref_topic=6061961
7. Регулярно переглядайте (і оновлюйте, якщо необхідно) файл robots.txt, щоб переконатися, що жодних проблем не існує
Багато що може статися під час розгортання, випусків коду тощо. Огляд файлу robots.txt у комбінації - такі інструменти, як Консоль пошуку Google допоможе переконатися, що ви правильно обробляєте індексацію вашого сайту та конфігурацію файлів robots.txt.
8. Використовуйте разом з тегом noindex на сторінці для кращого керування індексацією
Блокування індексування URL-адрес за допомогою файла robots.txt може не забороняти ці сторінки / файли відображатись як URL-адреси лише в списках SERP - особливо якщо сторінки індексувалися до їх виключення.
Якщо сторінка вже проіндексована, але заблокована, у SERP буде показано наступне повідомлення:
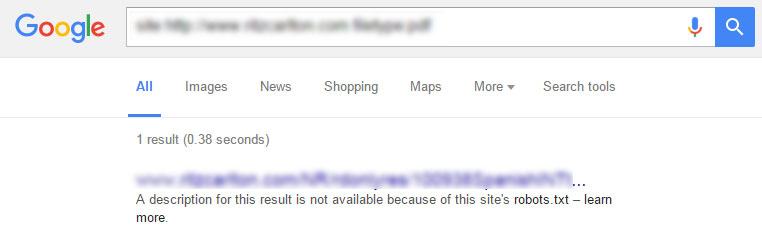
Найкращим рішенням для повного блокування індексу конкретної сторінки є використання [su_highlight] робота meta noindex [/ su_highlight] тега на кожній сторінці поряд з файлом robots.txt.
Це найкращий спосіб припинити потрапляння сторінок до індексу в першу чергу, а також отримати індексовані сторінки для видалення.
Рекомендована конфігурація для WordPress?
Якщо ви використовуєте WordPress, дуже легко редагувати файл robots.txt, використовуючи FTP або плагін, такий як Yoast SEO для Worpress. Просто виконайте такі дії, щоб внести зміни до файлу robots.txt .
З точки зору найкращого способу налаштування, існує багато способів шкіри кішки.
Нижче наведено налаштування шахти:
Агент користувача: * Disallow: / wp-content / plugins / Allow: /wp-content/plugins/*.jpg Дозволити: /wp-content/plugins/*.gif Дозволити: /wp-content/plugins/*.png Дозволити: /wp-content/plugins/*.css Дозволити: /wp-content/plugins/*.js Disallow: / wp-admin / Sitemap: https://jacobstoops.com/sitemap_index.xml
Ми переконалися, що ключовий вміст буде скануватися, але ця конфігурація забезпечить блокування ключових каталогів, дозволяючи індексувати речі, такі як Javascript, CSS і зображення.
Я також включив посилання на мій файл індексу sitemap XML.
Додаткові ресурси Robots.txt
Кредит із зображенням: Диск E-News
Txt?Чому цей файл настільки важливий?
Ви технічно це потребуєте?
Txt для SEO?
Txt?
Txt?
Ви технічно це потребуєте?
Txt для SEO?
Com/webmasters/answer/6062598?
Рекомендована конфігурація для WordPress?