



Screaming Frog - это популярный инструмент для улучшения собственного сайта в области поисковой оптимизации. Таким образом, например, очень легко найти использование повторяющихся заголовков и описаний или даже незарегистрированных ссылок на страницы ошибок. Помимо этих функций, в этом инструменте есть еще много чего. В частности, новые функции увеличивают возможности приложения в поисковой оптимизации в несколько раз. В этом руководстве вы получите множество практических приложений для демонстрации возможностей Screaming Frog, а также пищу для размышлений для тестирования собственных приложений.
Screaming Frog - это так называемый инструмент для сканирования , который можно легко установить в виде программы на Windows и Mac. Простота использования делает его одним из самых популярных инструментов в поисковой оптимизации. В частности, нововведения 2015 года значительно расширили возможности Screaming Frog и их популярность. Вы можете выполнить полный контент и технический аудит вашего собственного сайта без особых усилий. В базовой версии можно бесплатно проанализировать 500 URL-адресов, для крупных веб-сайтов следует использовать экономичную версию Pro.
Кричащая лягушка - Инновации 2015
Создатели Screaming Frog были более чем усердны в 2015 году. Снова и снова были серьезные обновления с новыми функциями, которые действительно есть. Следующие три функции обязательно должны быть упомянуты и представлены более подробно:
- Пользовательский поиск - Пользовательский поиск позволяет искать в исходном коде любой контент. В специальном фильтре «вкладка» вы можете распечатать обе страницы, которые содержат контент в исходном коде, а также страницы, которые не содержат контент. Таким образом, например, в форме аудита контента легко определить, существует ли текст в категориях в онлайн-магазине.
- Custom Extraction - Custom Extraction позволяет, например, читать контент с веб-сайта, используя CSS Path. В дополнительной таблице вы можете, например, извлекать количество комментариев ко всем статьям блога или полному контенту, которые всегда находятся в исходном коде в одном и том же месте.
- Google Search Console и подключение к Google Analytics API . Возможность запуска данных о трафике из Google Search Console или Google Analytics непосредственно в Screaming Frog открыла новые возможности, особенно в отношении приоритезации контента. Например, можно отсортировать страницы, которые генерируют наибольшее количество трафика, чтобы дополнительно улучшить их или укрепить их с помощью внутренних ссылок или, наоборот, для выявления потенциальных возможностей.
Три функции, описанные подробно, не следует недооценивать. Они открывают новые возможности применения и могут быть объединены друг с другом по мере необходимости.
Практические приложения, которые вы должны знать
Наиболее важные функции в Screaming Frog уже были представлены, теперь пришло время реализовать и представить некоторые из готовых приложений. Представленные возможности приложения могут быть имитированы непосредственно для собственного веб-сайта и в то же время должны служить пищей для обдумывания собственных прикладных идей с помощью этого инструмента.
Управление индексированием с помощью Screaming Frog
Управление индексом может быть описано как элементарный компонент хорошей поисковой оптимизации. Только получив контроль над индексацией вашего собственного сайта, вы сможете влиять на то, какие страницы Google использует для оценки сайта, и даже будет иметь возможность ранжировать и создавать новые целевые страницы.
Самый простой способ получить контроль над индексацией - это использовать Sitemap Index из Google Search Console. Вы отправляете в Google файлы Sitemap со всеми важными или релевантными для продажи страницами и просите поисковую систему включить эти страницы в индекс. Но именно здесь возникают первые проблемы: Google нередко включает в индекс только часть необходимого контента.
Это большой убийца, особенно в интернет-магазинах. Каждая страница интернет-магазина в индексе имеет возможность генерировать трафик, который, в свою очередь, приносит доход. Теперь, если 20% интернет-магазина вообще не проиндексированы, оператор интернет-магазина может относительно быстро подсчитать, что здесь теряется для продаж. Поэтому основной целью должно быть включение в индекс всех релевантных для продаж страниц.
После загрузки файла XML Sitemap в консоль поиска Google, Google показывает, сколько вложенных страниц вы хотите проиндексировать и сколько вложенных страниц Google фактически проиндексировало.
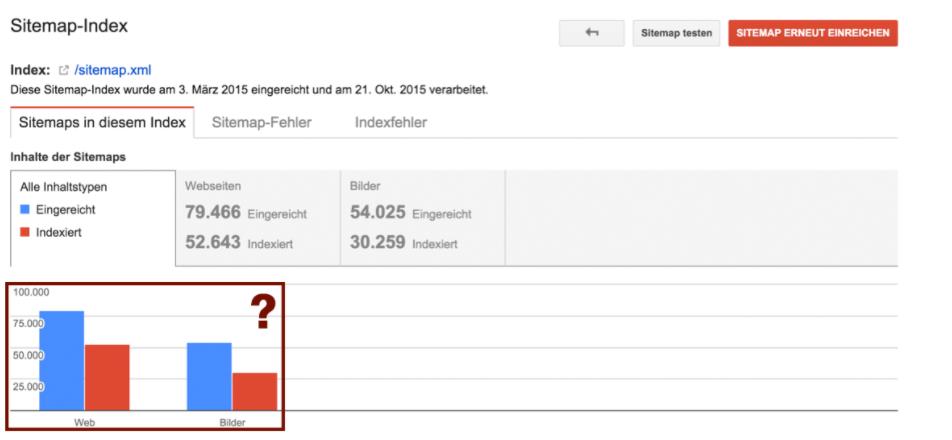
В приведенном выше примере легко увидеть, что из 79 466 страниц были проиндексированы только 52 643 страницы. Это различие между отправленными и неиндексированными страницами не является редкостью при первом исследовании индексации карты сайта, что обеспечивает большой потенциал оптимизации.
Почему это различие даже дано и что с этим можно сделать? Существует две основные причины различия между отправленными и проиндексированными страницами. Основная причина в основном из-за прямого XML-файла Sitemap :
Поиск ошибок в XML-файле Sitemap с помощью Screaming Frog
Немногие веб-сайты могут утверждать, что карта сайта на 100% чиста. Нередко они отправляются с помощью файла Sitemap на страницы Google, которые не могут быть проиндексированы в конце. Причины могут быть, например, следующие:
- Подстраницы больше недоступны, потому что, например, содержимое было удалено или существуют проблемы с сервером - тем не менее, эти стороны все еще часто можно найти в XML Sitemaps
- Подстраницам было присвоено значение noindex, что исключало их из индексации, однако эти страницы по-прежнему часто встречаются в файлах Sitemap XML.
- Подстраницы содержат канонический тег, который указывает на другую страницу. Обычно это индексирует только страницу, указанную каноническим тегом, но эти страницы все еще часто встречаются в файлах Sitemap XML.
Чтобы избежать вышеупомянутых пунктов, необходимо контролировать свой собственный файл Sitemap в формате XML и тщательно его очищать. Именно здесь Screaming Frog может оказать большую поддержку. Используя функцию загрузки списка , мы можем импортировать наш XML-файл сайта непосредственно в Screaming Frog и немедленно начать сканирование каждой отдельной подстраницы. В зависимости от размера карты сайта вы вскоре получите полную оценку каждой подстраницы, которая включена в карту сайта.
Какие подстраницы вообще доступны для Google - На вкладке « Коды ответов» вы получите соответствующий код состояния HTTP для каждой страницы.
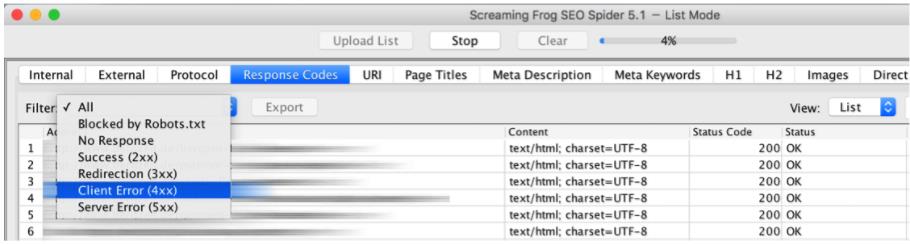
В итоге вы получите список следующей информации:
- Заблокировано Robots.txt - Какие страницы в настоящее время заблокированы через robots.txt и поэтому не могут быть проиндексированы Google
- No Response - Какие страницы вообще не возвращают код состояния и не могут быть проиндексированы Google
- Успех (2xx). Какие страницы возвращают код состояния 200 и поэтому доступны и индексируются Google
- Перенаправление (3xx). Например, какие страницы перенаправляются на другую страницу с помощью перенаправления 301 и поэтому не могут быть проиндексированы Google
- Ошибка клиента (4xx) - на каких страницах, например, выводится код состояния 404, и, следовательно, он больше не доступен
- Ошибка сервера (5xx) - какие страницы выдают код состояния 500 из-за ошибки сервера и не могут быть проиндексированы Google
Это много информации, которую Screaming Frog может предоставить в кратчайшие сроки, и опять же множество причин, по которым Google вообще не может индексировать страницы карты сайта. Поэтому после сбора всех кодов состояния необходимо предпринять шаги для окончательного удаления этих подстраниц из карты сайта.
Какие страницы вообще не могут быть проиндексированы оператором Noindex от Google. На вкладке Директивы вы можете выбрать фильтр Noindex и получить все страницы, для которых было установлено значение Noindex.
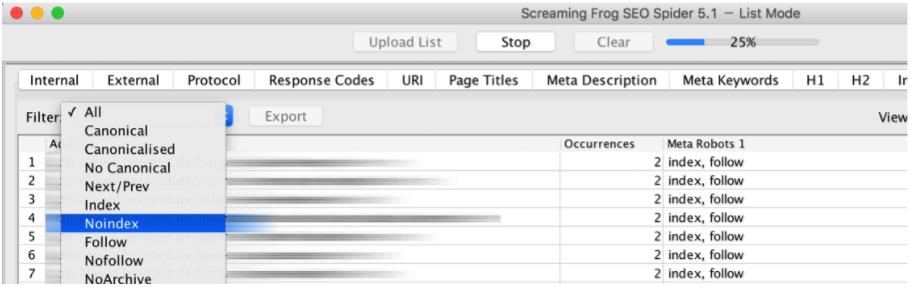
Опять же, Google не имеет смысла просматривать содержимое файла Sitemap, чтобы показать, что он, в свою очередь, вообще не может быть проиндексирован для Google. Опять же, нужно предпринять шаги, чтобы навсегда удалить эти подстраницы из карты сайта.
Какие страницы ссылаются на другую страницу через тег Canonical - На вкладке Директивы вы можете выбрать фильтр Canonicalised и получить все страницы, которые ссылаются на другую страницу через тег Canonical.

Всякий раз, когда Canonicalical указывает на другую страницу, а не на себя с одной страницы, эта страница должна навсегда исчезнуть из XML Sitemap. В противном случае вы предлагаете Google только страницы для индексации, которые, в свою очередь, не могут индексировать себя.
На основе последних трех запросов о Screaming Frog вы можете увидеть высокий потенциал ошибок в XML-карте сайта, а также то, насколько легко ошибки в пределах карты сайта можно найти именно с помощью этого инструмента.
Если все ошибки в пределах карты сайта могут быть обнаружены, и они, в свою очередь, будут решены, то есть в будущем навсегда исчезнут из карты сайта, в будущем у вас будет очень хороший способ отправить только соответствующий контент в Google. Это также даст вам гораздо меньшую разницу между отправленными и проиндексированными страницами через консоль поиска.
Другая причина не индексации страниц в представленной карте сайта связана не с самой картой сайта, а с недостатком самого качественного контента. Возможно, Google не индексирует следующие страницы:
- Google может не включать в индекс страницы с небольшим уникальным контентом ( тонким контентом ). Такие страницы должны быть обогащены высококачественным контентом по мере необходимости или должны быть без индекса, чтобы предотвратить отправку негативных сигналов в Google.
- Страницы, которые вообще не связаны или имеют очень мало внутренних данных - здесь индексация может занять много времени, несмотря на карту сайта, или вообще не выполняться. Если такие страницы все еще важны, структура страницы или внутренние ссылки должны быть улучшены
- Страницы с высоким содержанием дублирующегося контента ( Duplicate Content ) могут быть исключены из индекса Google - такие страницы должны либо обогащаться высококачественным контентом, либо полностью избегаться, либо храниться вне Google
Все эти причины могут быть проанализированы с помощью Screaming Frog для вашего собственного содержимого файла Sitemap. Прежде всего в Screaming Frog все ранее определенные ошибки, такие как коды состояния, должны быть удалены напрямую ( правая кнопка мыши - Удалить ). Затем вы можете экспортировать этот список в файл Excel и получить тем самым список всех сторон, которые должны быть включены в будущем в окончательную карту сайта.
Сопоставьте Sitemap с Google Index и найдите причины для неиндексированных страниц
Интересно выяснить, какие страницы в этом списке еще не проиндексированы Google, и проанализировать причины этого. Хотя процент страниц, которые не были проиндексированы, получен через консоль поиска, вы не получаете сами страницы, поэтому вам необходимо знать, что делать. Для небольших сайтов вы также можете использовать Screaming Frog здесь.
Если вы хотите выяснить, включена ли страница в Google в индекс, вы можете запросить наличие веб-кэша Google в дополнение к запросу сайта. Если вы хотите, например, проверить, находится ли стартовая страница WebsiteBoosting в кэше Google, достаточно выполнить следующий запрос:
http://webcache.googleusercontent.com/search?q=cache:https://www.websiteboosting.com/
Если для этого запроса есть URL-адрес, можно также предположить, что именно эта страница содержится в индексе. Если нет, вы попадаете на страницу с ошибкой. Именно эти знания мы можем использовать, связав все страницы в нашем списке Excel следующим образом:
http://webcache.googleusercontent.com/search?q=cache:[URL1 ]
http://webcache.googleusercontent.com/search?q=cache:[URL2 ]
http://webcache.googleusercontent.com/search?q=cache:[URL3 ]
Отсюда вы получите список, который можно импортировать в инструмент через уже упоминавшуюся функцию импорта Screaming Frog.
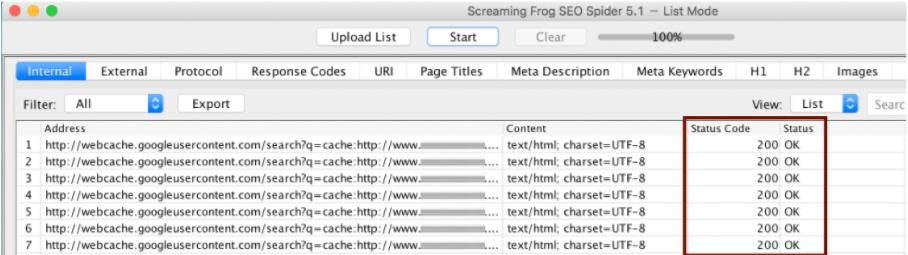
После обхода отдельных страниц можно получить обратную связь по коду состояния, независимо от того, существует ли на соответствующих сторонах сторона веб-кэша Google ( код состояния 200 ) или нет ли стороны веб-кэша Google (код состояния 400), и может ли эта информация непосредственно использоваться для индексации Перенос страниц в Google.
Поскольку Google с течением времени выдвигает автоматические запросы с помощью панели запросов капчи, вам следует уменьшить максимальное количество запрашиваемых URL-адресов в секунду до минимального значения 0,1. Это можно сделать в разделе « Конфигурация - Скорость» .
Однако для больших страниц рекомендуется использовать инструменты запросов индексации Google, которые позволяют использовать различные прокси. Здесь, например, инструмент URL Profiler можно использовать → http://urlprofiler.com/.
В конце вы должны получить список всех неиндексированных страниц, и, таким образом, вы точно знаете, какие страницы из XML Sitemap еще не найдены в индексе Google. Если вы сравните этот список со сканированием сайта, вы получите ценную информацию об этих страницах.
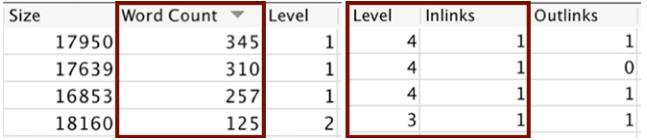
Следующие причины неиндексации могут быть прочитаны, например, из Screaming Frog Crawl:
- В столбце Word Count вы можете увидеть, какие страницы содержат очень мало контента. Все слова на соответствующей странице складываются вместе. Если вы посмотрите на соответствующий пример, например, 125, но также и 345 слов, это очень мало общего содержания на странице.
- В столбцах Level и Inlinks вы можете идентифицировать страницы, которые редко или не имеют внутренних ссылок. Столбец Уровень описывает количество кликов от домашней страницы. Столбец Inlinks описывает количество внутренних ссылок, указывающих на соответствующую подстраницу. Страница, которая находится в 4-х кликах от главной страницы и доступна только по ссылке, в глазах Google играет очень незначительную роль, и ее также сложно найти в Google Bot.
- Даже сайты, которые вызывают дублирование контента, можно найти с помощью Screaming Frog. Однако, поскольку существует несколько возможностей, этот вопрос будет обсуждаться в следующей главе.
На первом шаге было показано, как сначала проверить функциональность вашей собственной карты сайта и определить страницы, которые не имеют бизнеса в этой карте сайта. На втором шаге вы можете увидеть, как найти страницы, которые можно проиндексировать, но которых нет в индексе в настоящее время. На последнем этапе мы смогли определить причины неиндексированных страниц и теперь можем соответствующим образом улучшить эти страницы, чтобы Google проиндексировал максимально возможное количество отправленных страниц в будущем.
Повторяющийся контент с Screaming Frog
Дублированный контент - это такой же или очень похожий контент, который можно найти по разным URL-адресам. Грубо говоря, можно различить внешний и внутренний дублированный контент.
- Внешний дублированный контент - веб-сайты, которые очень похожи или даже содержат одинаковый контент на своих страницах, затрудняют оценку различных веб-сайтов для поисковой системы. Внешний дублированный контент создается, например, с помощью текстов производителей или передачи данных о продуктах филиалам и поисковым системам цен.
- Внутренний дублированный контент - гораздо чаще встречается дублированный контент на вашем собственном домене. В этом случае Google (а также пользователь) находит идентичный контент на страницах с разными URL. Проблема в том, что Google решает, какая из двух сторон показана, а какая скрыта. Кроме того, linkjuice распространяется на две страницы, а не концентрируется на одном URL. Например, внутреннее дублированное содержимое может быть создано с помощью индексируемых страниц фильтра или страниц разбиения на страницы.
Чтобы избежать дублирования контента, вы можете использовать мета-тег Robots Noindex , Canonical Tag или даже robots.txt . В то же время можно изменить затронутые страницы, чтобы Google воспринимал их как уникальные (например, через уникальный контент).
Прежде всего, найти дублированный контент на вашем собственном сайте сложнее. Указанием на дублированный контент являются дубликаты заголовка и описания. Частично, вы также можете получить доступ к консоли поиска в разделе HTML для улучшения этой информации.
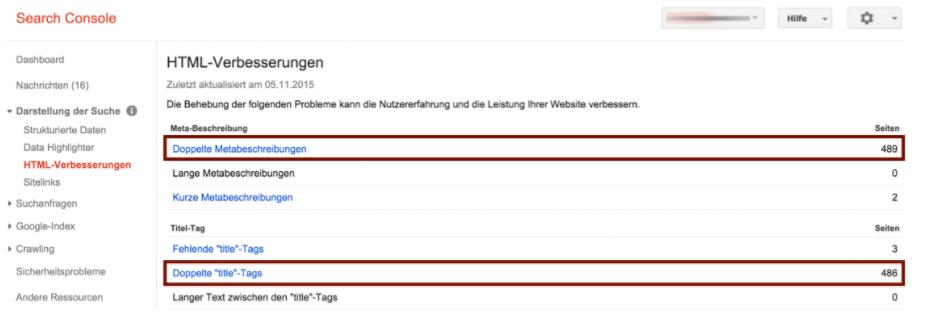
Проблема с консолью поиска, однако, заключается в том, что данные частично неполны и не обновлены. Поэтому, чтобы получить полное состояние всех дублированных метатегов, вы должны использовать Screaming Frog или инструмент для сканирования.
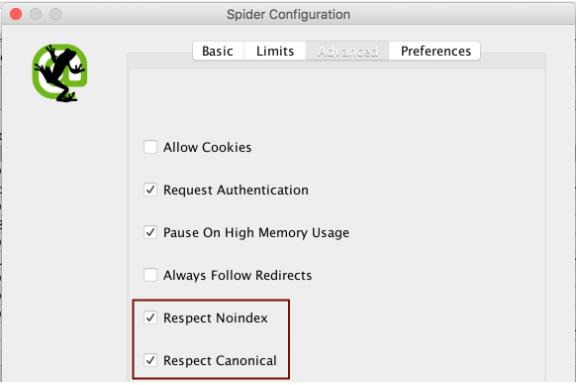
Важным здесь является параметр, при котором Screaming Frog сканирует только те страницы, которые также могут быть проиндексированы Google. Страницы, которые находятся, например, на Noindex, теоретически могут содержать дублированный контент, но не индексируются и не индексируются Google и, следовательно, не являются проблемой. Настройку (см. Рис. 8) можно найти в разделе « Конфигурация - Паук» на вкладке « Дополнительно ».
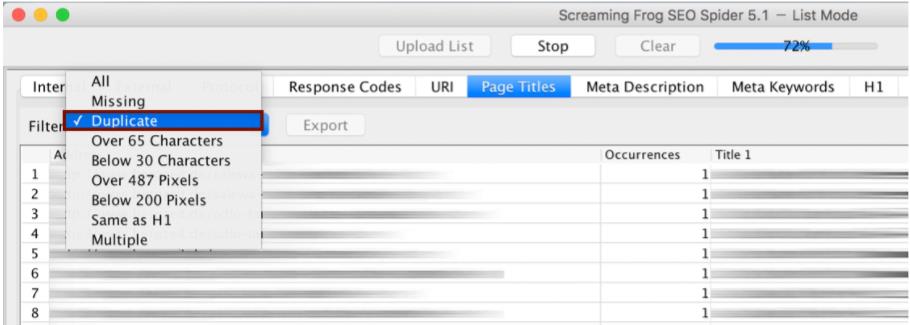
После настройки этого параметра вы можете отправлять Screaming Frog в путешествие и сканировать его на индексируемые веб-страницы. Таким образом, человек получает исчерпывающие данные и может точно прочитать, какое название и описания встречаются вдвойне в настоящее время. Информацию о дублированном заголовке можно найти, например, на вкладке « Заголовки страниц » под фильтром « Дубликат».
Другой способ идентификации с использованием дублирующего контента Screaming Frog - через значение хеш- функции. Screaming Frog определяет значение хеша из существующего исходного кода для каждой страницы. Если несколько страниц полностью идентичны, значение хеш- функции одинаково. Чтобы определить дублирующийся контент, в столбце Hash нужно определить только два значения.
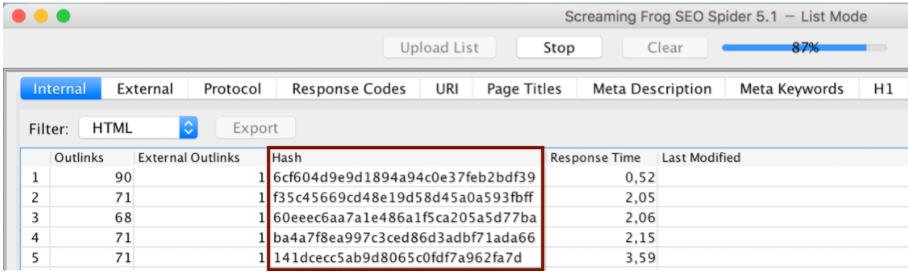
Два вышеупомянутых метода могут использоваться для поиска содержимого, такого как страницы фильтра или страницы нумерации страниц внутри веб-страницы. Из-за повторяющихся шаблонов обычно достаточно примеров, чтобы найти этот тип дублированного контента. Интернет-магазины могут также иметь дополнительный внутренний дублированный контент из-за многократного использования текстов продуктов.
С помощью Screaming Frog и функции Custom Extraction контент с веб-сайта может быть полностью извлечен и впоследствии исследован на предмет дублирования. Если, например, вы хотите вывести все тексты продуктов, чтобы проверить их на наличие дубликатов, эта функция идеально подходит.
Для использования функции Custom Extraction , CSS Path или XPath необходимы именно там, где находится контент. Вы должны действовать следующим образом: сначала отметьте любой текст продукта и щелкните правой кнопкой мыши. Затем вы можете выбрать функцию Copy CSS Path через Chrome.
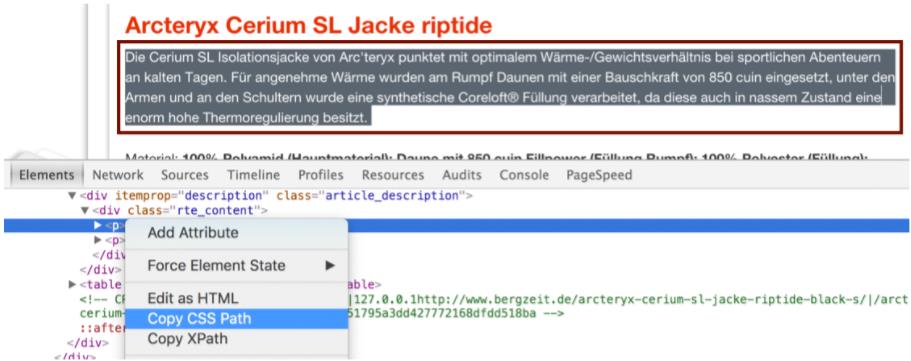
У вас уже есть CSS Path в кэше и вы можете продолжать его использовать. Под Конфигурация - Пользовательский - Извлечение теперь вы можете выбрать любое имя для соответствующего столбца. Кроме того, выберите CSSPath и вставьте код из кэша в соответствующее поле. В следующей функции выбора Извлечь текст выбирает, что вы хотите извлечь только текст без элементов HTML.

После сканирования все тексты продуктов соответствующего интернет-магазина теперь доступны в новом столбце и могут быть легко перепроверены, например, в Excel.
С помощью Screaming Frog источники для дублированного контента могут быть определены быстро и легко. С помощью дублирующих заголовков и описаний вы можете особенно найти шаблоны для дублированного контента. Полностью идентичное содержимое можно определить с помощью значения хеш-функции. Напротив, тексты продуктов в интернет-магазинах могут быть полностью извлечены, а затем проверены на предмет повторного использования.
Освойте повторный запуск с Screaming Frog
Перезапуск веб-сайта всегда связан с важными соображениями и решениями с точки зрения SEO, особенно если необходимо изменить полную структуру URL. На регулярной основе вы можете читать о веб-сайтах, которые сильно пострадали из-за - с точки зрения SEO - неудачного перезапуска.
Как для подготовки, так и после повторного запуска мы можем предпринять необходимые шаги с помощью Screaming Frog.
Перед повторным запуском. Прежде всего, важно создать так называемый план перенаправления перед повторным запуском. Если, например, полная структура URL-адреса изменится, нам нужно немедленно перенаправить Google Bot и пользователя в новое место назначения с помощью 301 перенаправления. В противном случае старые URL-адреса просто никуда не делись, и, кроме того, все рейтинги в Google исчезли бы в одночасье. Также раздражает, когда подстраницы имеют высококачественные внешние ссылки и просто полностью забываются во время повторного запуска.
В плане перенаправления Screaming Frog использует общий обход страницы, чтобы помочь нам охватить все релевантные и доступные в настоящее время подстраницы. Здесь также следует позаботиться о том, чтобы сканировались только страницы, которые могут быть проиндексированы Google (см. Рис. 8). После экспорта этих данных у нас уже есть шаблон для нашего плана перенаправления, и мы можем решить, какие страницы должны указывать на будущее с помощью перенаправления 301.
Имеет смысл сделать так называемое Basic Onpage SEO Backup перед повторным запуском. Это включает в себя резервное копирование всех соответствующих факторов на странице, таких как заголовок, описания, контент, а также информация о мета-роботах и канонические теги. За исключением содержимого, у нас уже есть все данные в рамках общего сканирования страницы, которые мы можем свободно экспортировать. Кроме того, с помощью функции Custom Extraction мы можем, например, извлечь тексты категорий интернет-магазина и мгновенно переустановить их, если в ходе повторного запуска произошла потеря.
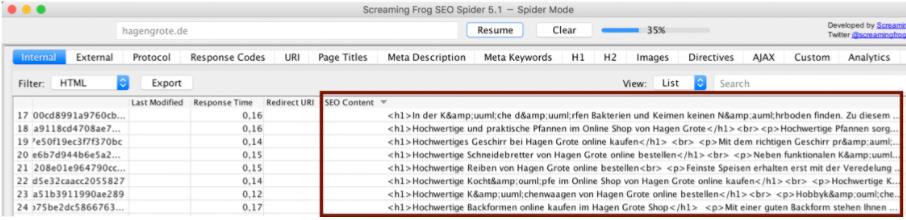
Как извлечь контент с помощью Cusom Extraction, уже было показано в разделе «Поиск дублированного контента» (см. Рис. 11-12). Чтобы получить существующие элементы HTML, такие как теги H1 или внутренние ссылки, необходимо использовать элемент Extract HTML вместо Extract Text .
После повторного запуска - сразу после того, как новая структура URL была активна, вы должны немедленно предпринять действия, чтобы найти возможные источники ошибок и как можно быстрее их очистить. С помощью плана перенаправления вы можете сравнить, все ли перенаправления были настроены правильно.
При импорте в Screaming Frog начнется сканирование старых URL-адресов. Если вы теперь получаете код состояния 301 для всех старых URL-адресов на вкладке « Коды ответов» , вы знаете, что вся переадресация была правильно сохранена. Однако, если появляются 404 кода состояния, запланированные перенаправления должны сохраняться во избежание потери рейтинга.
Даже новое полное сканирование страницы не повредит. В частности, вы можете обнаружить неправильно поддерживаемые внутренние ссылки, которые, например, ссылаются на страницу с ошибкой 404.
Для веб-контроля важно, чтобы все данные проходили гладко после перезапуска и чтобы не было разрыва. Такой пробел в данных может возникнуть, например, если при случайном перезапуске на отдельных страницах или шаблонах интеграция кода отслеживания отсутствует. С помощью пользовательского поиска вы можете отправить Screaming Frog в путешествие и попросить его проверить все подстраницы для существующего кода отслеживания. Таким образом, каждый получает оценку, по каким сторонам, потому что код отслеживания в настоящее время еще не интегрирован. Пользовательский параметр поиска находится в разделе « Конфигурация - Пользовательский - Поиск» . Например, в зависимости от того, хотите ли вы изучить Google Analytics или код менеджера тегов Google, возможны разные фрагменты кода.

Например, фильтр 1 выводит все страницы, содержащие идентификатор диспетчера тегов Google в исходном коде. Фильтр 2, однако, прямо противоположен, а именно всем страницам, в которых этот идентификатор не включен в исходный код.
Screaming Frog поддерживает как до повторного запуска, так и непосредственно после повторного запуска. Оба показанных приложения необходимы для чистого перезапуска с точки зрения SEO, и им никогда не следует пренебрегать.
вывод
Возможности применения с Screaming Frog разнообразны. Такие функции, как пользовательский поиск и извлечение Costom , привели к новым способам сканирования в этом инструменте. Будь то полный контент и технический аудит, усовершенствование карты сайта XML, обнаружение дублированного контента или даже поддержка повторного запуска - Screaming Frog часто является правильной альтернативой и по-прежнему содержит в себе бесчисленные возможности приложений. Удачи и удачи с кричащей лягушкой!
Похожие
SEO инструмент: Screaming Frog SpiderСегодня я хотел бы начать с новой стороны в блоге, чтобы начать говорить об инструментах SEO, которые я считаю важными и которые я использую ежедневно, и исследовать очень много других инструментов, которые существуют на рынке и которые очень полезны в качестве поддержки в нашем проекты. Я начну с Screaming Frog (Spider SEO). Screaming Frog 4 важных конкурентных пункта данных SEO, которые вы всегда должны смотреть
... знать, какая доля трафика поступает через обычный или платный поиск. Возможно, вам придется нажать на некоторые плечи в отделе платного поиска, чтобы они начали проводить быстрый конкурентный мониторинг, точно так же, как вы делаете в SEO, если вы видите, что платный поиск набирает значительную долю поискового ресурса. индексация Мне часто Глоссарий. Что такое кричащая лягушка - SEO Tool
... вы имеете дело с (относительно) небольшими сайтами, оно позволяет выполнять очень подробное сканирование веб-сайта, даже если он не ваш (может быть очень полезным для анализа конкурентов). Как это работает? Ну точно как паук (или гусеничный ) поисковых систем, производит полную проверку сайта, который вы хотите проанализировать (просто введите URL-адрес домашней страницы любого сайта), быстро возвращая Почему вы должны вес поисковой оптимизации в Турции?
... которые служат хостом поисковой системы: При рассмотрении периодов с июня 2010 г. по июнь 2015 г. глобальная поисковая система Google.com занимает первое место. Особенно в ноябре 2011 года с увеличением использования Google.com занимает второе место и SEO: что нужно знать
Наблюдайте за трафиком на новом веб-сайте, и вы, вероятно, потеряли сознание от скуки между посетителями. Итак, как большие сайты сегодня увеличивают трафик от 0 до тысяч или даже сотен тысяч уникальных посетителей в день? Поисковая оптимизация (SEO) это маркетинговая 8 вещей, которые нужно знать о поисковой оптимизации (SEO)
Олатунджи Адетунджи Поисковая оптимизация, SEO. Кредит изображения: innobyte.com Ниже приведены обычные критерии SEO, на которые следует обратить внимание отдельным лицам или компаниям, прежде 3 случая, когда вы не должны самостоятельно управлять своим SEO
... знать и слишком много. Если в прошлом вы пытались самостоятельно управлять, и у вас ничего не получалось, попробуйте еще раз. Вы не профессионал SEO; Ничего страшного в этом нет. Аутсорсинг, чтобы вы могли сосредоточиться на тех областях, где вы действительно преуспели. Самоуправление SEO может быть возможным, но вы должны сосредоточиться на общей картине бизнеса. Иногда самой большой силой для вашей компании может быть признание того, что у вас есть проблема и вам нужна помощь, как 6 из лучших плагинов, которые вы должны установить на веб-сайте WordPress
... вы должны установить. Что это за плагины? Пожалуйста, обратитесь к этой статье до конца! Лучшие рекомендации плагинов, которые вы должны установить на веб-сайте WordPress 1. Йост SEO Yoast SEO Лучший плагин, который вы должны сначала установить - это Yoast Экономичные SEO услуги, которые работают
... которые принадлежат кибер-миру. Одна из вещей, которую предлагают компьютерные системы или кибер-мир, - это Интернет. Интернет - большая вещь, которая предоставляет множество услуг. В сети вы можете найти все, что вам нужно. Учитывая, что Интернет, скорее всего, управляет всем, что существует в этом мире, все компании и частные лица, которые предлагают услуги и продукты, используют Интернет для своих маркетинговых, продаж, рекламных и других аспектов компании и жизни. В сердце моря Викторины из фильма: 20 вещей, которые нужно знать
В 1819 году китовый корабль Эссекс отплыл из Нантакета с экипажем из 20 человек, который отправлялся на охоту на китов, чья нефть была ответственна за процветающую экономику Новой Англии. Лучшие SEO приложения для iPhone
... приложения для поисковой оптимизации iPhone (и iPad). В мире SEO мы всегда ищем новые уникальные советы по улучшению рейтинга в поисковых системах, и, похоже, профессионалы SEO с удовольствием дадут свои советы в бесплатных приложениях для iPhone. Я просматривал AppStore / iTunes в поисках полезных приложений, которые бы давали советы и подсказки для новых поисковых систем, с которыми я, возможно, не сталкивался. Вот что я нашел до сих пор:
Комментарии
Вы искали или заставляли кого-то искать в LinkedIn названия и ключевые слова, которые вы использовали в своем профиле, чтобы увидеть, где вы занимаетесь, не так ли?Вы искали или заставляли кого-то искать в LinkedIn названия и ключевые слова, которые вы использовали в своем профиле, чтобы увидеть, где вы занимаетесь, не так ли? Проанализируйте свой рейтинг в LinkedIn для поиска по названию и ключевым словам Я искал в 25-мильном радиусе моего почтового индекса с этими тремя словами в поле названия, выбирая текущий: набор вице-президента, и я сортировал по ключевым словам. Если вы вошли в систему, Сколько вы должны написать и как часто вы должны публиковать?
Сколько вы должны написать и как часто вы должны публиковать? Потому что рост визуального контента который мы увидим в 2014 году, мы увидим падение в длинных, насыщенных фактами статьях блога. Интернет-пользователи и читатели блогов хотят получать информацию быстро, легко и удобно. Блог вашего бизнеса должен отражать это. Сосредоточьтесь на балансе вашего контента. Иногда предлагайте Здесь вы должны использовать немного логики: если за 30 евро в месяц вы будете на первых страницах Google в очень короткое время, не думаете ли вы, что мы все сделаем то же самое?
Здесь вы должны использовать немного логики: если за 30 евро в месяц вы будете на первых страницах Google в очень короткое время, не думаете ли вы, что мы все сделаем то же самое? Если за 30 евро вы можете умножить на 10 или 20 количество посещений за 3 месяца, это действительно будет выгодно. И мы все подумаем, завтра я построю «обувной магазин в Мадриде» . Наш ИТ-консалтинг , César IT Consultores, покажет вам технические усовершенствования, чтобы ваше позиционирование Как еще вы поймете, как люди реагируют на ваш сайт, если вы не посмотрите, выполняют ли они действия, которые вы от них хотите?
Как еще вы поймете, как люди реагируют на ваш сайт, если вы не посмотрите, выполняют ли они действия, которые вы от них хотите? Как использовать показатель отказов Теперь, когда мы получили неправильные представления, давайте поговорим о нескольких правильных способах использования показателя отказов для оценки эффективности вашего сайта. Показатель отказов + [метрика] Чтобы определить контекст отказов, подумав о сопряжении его с другим показателем, таким как Когда вы переходите по гиперссылке на другую страницу, думаете ли вы о том, как вы используете якорный текст, или вы относитесь к человеку типа «нажмите здесь» (вставьте гиперссылку)?
Когда вы переходите по гиперссылке на другую страницу, думаете ли вы о том, как вы используете якорный текст, или вы относитесь к человеку типа «нажмите здесь» (вставьте гиперссылку)? Поскольку у меня есть для вас новости, хотя, возможно, имеет смысл попросить ваших читателей «кликнуть здесь, чтобы продолжить чтение», для поисковых систем это бесполезно. Назовите их суетливыми, но им нужно описание того, на что вы ссылаетесь. Например, если вы ссылаетесь на другую статью, которую Сообщество дизайнеров хочет знать: почему дизайнеры должны знать SEO?
Сообщество дизайнеров хочет знать: почему дизайнеры должны знать SEO? Можете ли вы дать мне свои 5 главных причин? Дизайн для пользователя. Подтвердите свое направление. Повысьте ценность своего профессионального мастерства. Увеличьте потребность в большем количестве дизайна, чтобы ориентироваться на различные тактики поиска. Определите ROI для вашей работы. Отлично. Вы Но это не только SEO… Помните ли вы все эти цифры, которые вы видите каждый раз, когда смотрите на Google Analytics?
Но это не только SEO… Помните ли вы все эти цифры, которые вы видите каждый раз, когда смотрите на Google Analytics? Эти данные представляют реальных, реальных людей ! Люди-люди любят ориентироваться на сайте, и ссылки - хороший способ сделать это. Используя текст привязки ключевых слов, вы также предоставляете полезные указатели, которые помогают пользователю перемещаться по сайту. Так что внутренние ссылки тоже улучшают пользовательский опыт! Это помогает показать Вы вооружены всем, что вам нужно знать, чтобы шаг за шагом создавать и оценивать видео на YouTube - чего же вы ждете?
Вы вооружены всем, что вам нужно знать, чтобы шаг за шагом создавать и оценивать видео на YouTube - чего же вы ждете? Повысьте рейтинг YouTube сейчас. Вы интернет-магазин с одеждой для молодых людей, которые могут позволить себе «более слабое» общение, или вы - компания-разработчик, которая серьезно относится к выступлению?
Вы интернет-магазин с одеждой для молодых людей, которые могут позволить себе «более слабое» общение, или вы - компания-разработчик, которая серьезно относится к выступлению? В ваших покупателях доминируют мужчины или женщины? Старше или моложе? Из столицы или из деревни? Все эти данные могут помочь вам уточнить вашу целевую аудиторию и помочь вам понять их потребности и привычки. Работа с доступными данными из консоли поиска Google Google Search Console - это отличный Как вы тратите свое время на вещи, которые, как вы знаете, приведут к результатам?
Как вы тратите свое время на вещи, которые, как вы знаете, приведут к результатам? Это то, что мы исследуем во время этого рабочего места. программа 15.00 | Двери открыты 15.15 | Мастер-класс SEO от Зовик Абрамов SEO - это термин, используемый для обозначения множества различных методов и методов, чтобы получить более высокий рейтинг в результатах поиска. Многие люди считают, что Не могли бы вы немного рассказать о некоторых трудностях и, возможно, о некоторых победах, которые вы имели по этим направлениям в рамках ABC?
Не могли бы вы немного рассказать о некоторых трудностях и, возможно, о некоторых победах, которые вы имели по этим направлениям в рамках ABC? Джон Шехата: Конечно. Я считаю, что от 40% до 50% нашей работы состоит в том, чтобы обучать и информировать людей о лучших практиках SEO, и мы действительно тратим на это много времени. Мы создаем разные презентации и адаптируем их к разным типам аудитории. Презентации на уровне C отличаются от презентаций для разработчиков
Почему это различие даже дано и что с этим можно сделать?
Com/search?
Com/search?
Com/search?
Com/search?
Как это работает?
Итак, как большие сайты сегодня увеличивают трафик от 0 до тысяч или даже сотен тысяч уникальных посетителей в день?
Что это за плагины?
Вы искали или заставляли кого-то искать в LinkedIn названия и ключевые слова, которые вы использовали в своем профиле, чтобы увидеть, где вы занимаетесь, не так ли?
Сколько вы должны написать и как часто вы должны публиковать?